

Информационное обеспечение АСУ – это совокупность единой системы классификации и кодирования технико-экономической информации, унифицированных систем документации и массивов информации, используемых в автоматизированных системах управления. Информационное обеспечение подразделяют на внемашинное и внутримашинное (рис. 1). К внемашинному информационному обеспечению относят: оперативную документацию, содержащую сведения о состоянии управляемого объекта и среды, нормативно-справочные документы, включающие систематизированную проектно-сметную, техническую, технологическую, организационную и производственную документацию, а также архивную информацию; систему классификации и кодирования информации; инструкции по организации ввода, хранения, внесения изменений в нормативно-справочную документацию, в том числе и в массивы данных о среде.
В процессе разработки задач АСУ проектирование информационного обеспечения обычно рассматривается как относительно самостоятельная часть общей разработки автоматизированной системы управления. Ввиду сложности и большой стоимости CASE-технологий и CASE-средств их применяют в настоящее время, как правило только для создания АСУ крупных организаций.
Основными компонентам базы данных являются: нормативно-справочная, плановая, оперативная, учетная информация (рис. 2). К плановой информации относится та часть нормативных данных, которые непосредственно связаны с организационно-технологическими моделями строительных объектов и плановыми ресурсами по строительным работам. Данные этой группы можно считать условно-постоянными.
Внутримашинная информационная база характеризуется составом и структурой массивов, способами организации и доступа к данным на машинных носителях. В зависимости от используемых программных средств организация массивов может иметь свои особенности. Существует два основных способа организации информационных массивов: а) в виде отдельных независимых файлов (файловая организация); б) быть в составе базы данных, являющейся интегрированной совокупностью взаимосвязанных массивов.
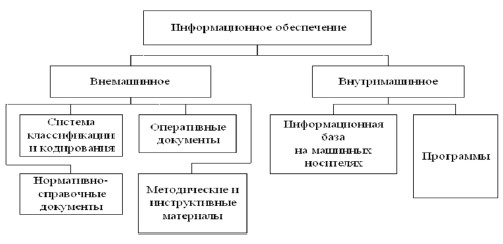
Рис. 1. Структура информационного обеспечения АСУ
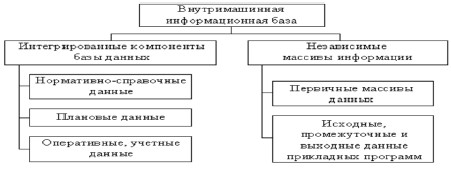
Рис. 2. Состав внутримашинной информационной базы
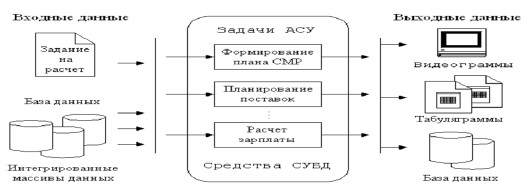
Рис. 3. Схема обработки массивов базы данных в задачах АСУ
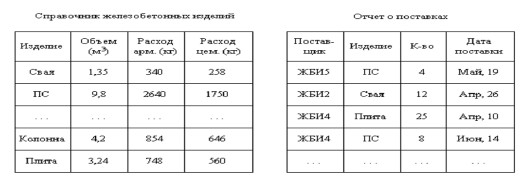
Рис. 4. Фрагмент реляционной модели базы данных
База данных, по существу, является интегрированной совокупностью недублируемой информации, на основе которой решаются большинство задач АСУ. Логические взаимосвязи в базе данных организуются в соответствии с тем, к какому типу она относится – иерархической, сетевой, реляционной. Существенным преимуществом базы данных является возможность многоаспектного доступа и использования одних и тех же данных различными задачами АСУ.
Для ускорения доступа к записям файла выполняется процедура индексирования, результатом которой является создание дополнитель-ного индексного файла, содержащего в упорядоченном виде все значения ключей файла данных. Для каждого значения ключа в индексном файле содержится указатель на соответствующую запись файла данных. Наличие индексного файла позволяет по заданному ключу быстро находить запись. Индексирование может производиться не только по первичному, но и по вторичному ключу.
Суть реляционной модели можно пояснить на следующем примере. Пусть в базе данных строительного предприятия имеются два файла: а) справочник железобетонных изделий; б) отчет о поставках изделий (рис. 4). Каждый из этих файлов содержит определенное число записей, состоящих из фиксированного числа полей (соответственно 4 и 4).
В данном фрагменте базы данных определены два отношения (файла), имеющие общий элемент значения поля Изделие. Операции реляционной алгебры могут объединить два типа записей по этому общему элементу. Например, в результате соединения запись ПС может представиться в следующем виде:
ПС <Объем (м3)><Расход арм. (кг)><Расход цем. (кг)><ЖБИ5><К-во><Дата поставки>.....
Чтобы не допустить потерь или искажения информации в реляционной базе данных необходим соответствующий контроль всех взаимосвязей записей. Этот контроль выполняется СУБД, которые в процессе работы постоянно пересчитывают число связей для каждой записи базы данных в прямом и обратном направлениях. При больших объемах баз данных осуществление такого контроля может потребовать существенных затрат машинного времени.