

Анализ параметров спектра речевого сигнала в процессе аутентификации производится на выходе полосовых фильтров, предназначенных для разделения полосы частот спектра исходного сигнала на непересекающиеся частотные области, так называемые спектральные каналы. Число полосовых фильтров Nф определяется известной методикой синтеза полосных вокодеров [1] и задается достаточно большим (Nф > 16). С этих позиций получено выражение для оценки ординат энергетического спектра речевого сигнала:
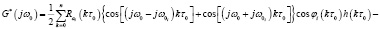
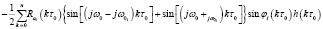 , (1)
, (1)
где τ0 – период дискретизации ; 0– шаг квантования по частоте; i – номер спектрального канала, определяемый из условия i = l, если ωHl ≤ jω0 < ωBl; ωHl и ωBl – соответственно нижняя и верхняя граничные частоты l-го спектрального канала.
Оценка ординат амплитудного спектра речевого сигнала получена на основании (1) из равенства
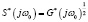 . (2)
. (2)
Выражения (7), (8) определяют алгоритм параметрического анализа и синтеза речевого сигнала в системах аутентификации.
Полученный алгоритм имеет ряд особенностей, отличающих его от известных алгоритмов параметрического анализа и синтеза речевого сигнала. Так, в качестве параметров спектра речевого сигнала здесь используются дискретные значения ковариационной функции огибающей 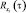 и фазовых соотношений
и фазовых соотношений 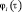 сигналов спектральных каналов. Это открывает возможность оценки любого числа ординат амплитудного спектра в процессе синтеза речевого сигнала. Число ординат амплитудного спектра N0, используемых в данном случае для синтеза речевого сигнала, не ограничивается числом полосовых фильтров анализатора Nф и может быть задано любым N0 > Nф путем выбора шага квантования по частоте при условии, что 0 < Bi – Hi, можно определять любое необходимое число ординат
сигналов спектральных каналов. Это открывает возможность оценки любого числа ординат амплитудного спектра в процессе синтеза речевого сигнала. Число ординат амплитудного спектра N0, используемых в данном случае для синтеза речевого сигнала, не ограничивается числом полосовых фильтров анализатора Nф и может быть задано любым N0 > Nф путем выбора шага квантования по частоте при условии, что 0 < Bi – Hi, можно определять любое необходимое число ординат 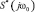 в пределах каждого спектрального канала. Очевидно, что точность восстановления огибающей спектра звука при синтезе речевого сигнала будет повышаться с увеличением N0, которое обеспечивается уменьшением шага квантования по частоте 0. Кроме этого, применение полученного алгоритма в вокодерных системах позволяет производить синтез речевого сигнала в целях аутентификации с учетом его фазовых соотношений.
в пределах каждого спектрального канала. Очевидно, что точность восстановления огибающей спектра звука при синтезе речевого сигнала будет повышаться с увеличением N0, которое обеспечивается уменьшением шага квантования по частоте 0. Кроме этого, применение полученного алгоритма в вокодерных системах позволяет производить синтез речевого сигнала в целях аутентификации с учетом его фазовых соотношений.