
Scientific journal
International Journal of Experimental Education
ISSN 2618–7159
ИФ РИНЦ = 0,827
MEASUREMENTS OF WEBOMETRIC INDICATORS

Еще в 2005 году в работе [1] было отмечено, что исследования Веба зачастую основываются на данных, полученных, если можно так выразиться, с помощью самого Веба, и, в частности, с использованием возможностей наиболее распространенных поисковых систем. Однако, поисковые системы, являясь коммерческими проектами, ориентированы на некоего условного «среднего» пользователя (с возможностью адаптации к его запросам), а не на исследователя.
Критические публикации на тему использования поисковых машин в качестве средств измерений появились достаточно давно [2-4]. Например, в работе [2] показано, что для подобранных конкретных примеров Google (по неизвестным причинам) «скрывает» от 48 до 70% проиндексированных им же страниц, содержащих ссылки на заданный сайт. Даже в случае очевидной ошибки в результатах вывода по запросу к поисковой системе мы не получим ответа на вопрос о том, почему эта ошибка произошла. Это, однако, не останавливает исследователей, имеющих в качестве «измерительных устройств» только поисковые системы [6, 7].
В процессе работы по проекту «Вебометрический рейтинг научных учреждений России» [5] в процессе измерений значений вебометрических индикаторов авторам пришлось столкнуться с возникновением ситуаций, которые нельзя назвать иначе как ошибками поисковых систем. Наиболее явно такие ситуации проявились при измерениях с помощью Google индикатора, характеризующего размер сайтов, когда получаемое количество страниц выражалось сотнями тысяч для сайтов весьма скромных размеров (об этом достоверно можно судить из других источников).
Поисковые системы как «измерительные устройства» обладают низкой надежностью, измерения, проведенные в одинаковых условиях, не всегда дают согласующиеся результаты [1]. Это объяснимо, если измерения проводятся через большие интервалы времени (сказывается динамика Веба), но неприемлемо в тех случаях, когда причин для больших расхождений не видно. Измерения индикаторов в рамках проекта [5] проводятся в течение компактного временного интервала (в течение двух недель) и дальнейшая обработка полученных значений не подразумевает новых замеров при обнаружении предполагаемых ошибок, поскольку в этом случае нужно заново измерять все индикаторы.
Однако ни в первом проекте по ранжированию веб-сайтов [8], ни в других проектах [6, 7], вопросу об ошибочных измерениях вебометрических индикаторов должного внимания не уделяется. В данной статье мы предложим подход к «сглаживанию» ошибок поисковых систем при измерениях размеров сайтов.
Вебометрические индикаторы. Общеизвестны основные вебометрические индикаторы, используемые при решении задач ранжирования веб-ресурсов. Можно считать, что 4 индикатора, введенные ещё в 2004 году в проекте [8], не вызывают принципиальных возражений и в настоящее время:
- размер сайта (S, size) – общее количество страниц,
- видимость сайта (V, visibility) – количество гипертекстовых ссылок с других веб-ресурсов,
- количество полнотекстовых файлов (R, «rich files», т.е. файлов с расширениями doc, pdf, ppt и т.д.),
- научность сайта (Sc, «scholar») – количество ссылок на сайт, обнаруживаемых Google Scholar.
Для первых трёх индикаторов следует добавить фразу «обнаруживаемых с помощью Google/Яндекс/ ...». Отметим также, что разработчики проекта [8] недавно анонсировали использование в качестве индикаторов данных, предоставляемых коммерческими системами Ahrefs Pte Ltd (https://ahrefs.com) и Majestic SEO (http://www.majesticseo.com), чем еще больше усугубили ситуацию в плане прозрачности и отсутствия коммерческих влияний [1].
В проекте «Вебометрический рейтинг научных учреждений России» для сбора значений вебометрических индикаторов используются поисковые системы Яндекс и Google и специализированная программа сбора внешних гиперссылок BeeCrawler [9].
Измерения вебометрических индикаторов. В проекте [5] на сегодняшний день проведены измерения индикаторов примерно для 400 сайтов РАН (далее количество сайтов будем обозначать N).
Пусть 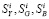 – размеры i-го сайта по Яндексу, Google и BeeCrawler, а
– размеры i-го сайта по Яндексу, Google и BeeCrawler, а 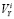 – видимость i-го сайта по Яндексу (она нам понадобится в разделе «Сглаживание ошибок»).
– видимость i-го сайта по Яндексу (она нам понадобится в разделе «Сглаживание ошибок»).
Приемы измерений поясним на примере сайта Российской академии наук (www.ras.ru). в Google на запрос вида «site:www.ras.ru» (текст набирается в поисковой строке, кавычки не нужны) будет выдан ответ «Результатов: примерно 513000». Это значение далее и будет принято в качестве 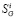 для сайта www.ras.ru (более точно – это значение
для сайта www.ras.ru (более точно – это значение 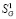 , поскольку сайт РАН имеет порядковый номер 1).
, поскольку сайт РАН имеет порядковый номер 1).
В Яндексе для получения количества страниц также можно использовать запрос вида «site:www.ras.ru». Ответ «Нашлось 85 тыс. ответов» округлен, хотя и его можно использовать в качестве приближенного значения 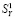 . Более удобным представляется использование специального сервиса Яндекс.XML, для чего необходимо зарегистрироваться в системе. Здесь запрос о количестве страниц на www.ras.ru выглядит следующим образом:
. Более удобным представляется использование специального сервиса Яндекс.XML, для чего необходимо зарегистрироваться в системе. Здесь запрос о количестве страниц на www.ras.ru выглядит следующим образом:
http://xmlsearch.yandex.ru/xmlsearch?text=site:www.ras.ru&user=USER&key=KEY,
где USER и KEY – логин и ключ пользователя. В одной из строк развернутого ответа на запрос будет строка <found−docs−human>нашёл 85145 ответов</ found−docs−human>, и 85145 будет являться значением индикатора 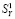 .
.
Удивляться существенному расхождению в результатах разных поисковых систем не следует: нам неизвестны правила отбора страниц на сайте, принятые в поисковых системах, и, по-видимому, в Google и Яндексе они различные. При последовательном просмотре результатов вывода Google вскоре выдаст информацию «Мы скрыли некоторые результаты, которые очень похожи на уже представленные выше (683)», то есть проверяемыми являются только 683 результата из 513000 заявленных, а что собой представляют остальные результаты проверить не удастся. Яндекс также выдает не все, а только 1000 ответов по запросу «site:www.ras.ru».
В BeeCrawler реализован порядок обхода страниц «вначале вширь»: сканируется начальная страница нулевого уровня, находятся страницы первого уровня, сканируются страницы первого уровня и находятся страницы второго уровня и т.д. В процессе сканирования создается вспомогательная таблица количества страниц на каждом уровне, т.е. мы имеем
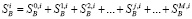 ,
,
где 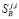 – количество страниц на j-м уровне i-го сайта, а М – номер наибольшего сканируемого уровня, устанавливаемого при запуске программы (в последней версии сканирования M=7).
– количество страниц на j-м уровне i-го сайта, а М – номер наибольшего сканируемого уровня, устанавливаемого при запуске программы (в последней версии сканирования M=7).
В табл. 1 приводятся значения индикаторов для нескольких веб-сайтов РАН.
Последние измерения, используемые в статье, проводились в июне-июле 2013 года. Полужирным шрифтом выделены значения 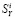 и
и 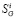 , которые представляются ошибочными. В частности, сайт Красноярского научного центра можно оценить визуально в любом браузере.
, которые представляются ошибочными. В частности, сайт Красноярского научного центра можно оценить визуально в любом браузере.
На рис. 1 приводятся значения размеров сайтов 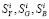 . Для удобства восприятия в едином масштабе значения
. Для удобства восприятия в едином масштабе значения 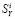 умножены на коэффициент 6 и упорядочены по убыванию, поэтому соответствующий график выглядит как непрерывная убывающая кривая, хотя и скрытая за пиками на заднем плане.
умножены на коэффициент 6 и упорядочены по убыванию, поэтому соответствующий график выглядит как непрерывная убывающая кривая, хотя и скрытая за пиками на заднем плане.
Таблица 1
Фрагмент таблицы значений вебометрических индикаторов
|
i |
Научное учреждение |
Имя сайта |
|
|
|
|
|
1 |
Российская академия наук |
www.ras.ru |
83013 |
606000 |
599904 |
20772 |
|
3 |
Отделение физических наук РАН |
www.gpad.ac.ru |
517 |
523 |
460 |
770 |
|
29 |
Пущинский научный центр РАН |
www.psn.ru |
5829 |
153 |
153 |
857 |
|
34 |
Красноярский научный центр СО РАН |
www.krasn.ru |
7291 |
93 |
1 |
500 |
|
44 |
Камчатский научный центр ДВО РАН |
www.kscnet.ru |
5757 |
177000 |
1525 |
6784 |
|
52 |
Библиотека по естественным наукам РАН |
www.benran.ru |
6471 |
177000 |
864 |
4154 |
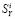
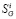
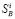
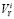
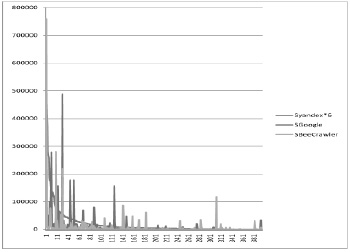
Значения 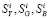 .
.
Графики по 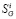 и
и 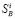 в черно-белом изображении не слишком выразительны и в основном характеризуют пики значений, подозрительных на ошибки. При этом регистрируемые ошибки по
в черно-белом изображении не слишком выразительны и в основном характеризуют пики значений, подозрительных на ошибки. При этом регистрируемые ошибки по 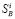 практически во всех случаях имеют содержательное объяснение: как правило, это так называемые «паучьи ловушки», когда разработчики сайтов (умышленно или неумышленно) создают условия для зацикливания поискового робота [10]. К ним относится организация меню сайта в виде дерева, динамические календари и т.д.
практически во всех случаях имеют содержательное объяснение: как правило, это так называемые «паучьи ловушки», когда разработчики сайтов (умышленно или неумышленно) создают условия для зацикливания поискового робота [10]. К ним относится организация меню сайта в виде дерева, динамические календари и т.д.
Обозначим 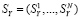 ,
, 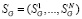 и
и 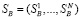 . Коэффициенты корреляции по Пирсону имеют следующие значения:
. Коэффициенты корреляции по Пирсону имеют следующие значения: 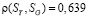 ,
, 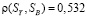 и
и 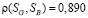 . Таким образом, можно говорить о высокой степени взаимосвязи между
. Таким образом, можно говорить о высокой степени взаимосвязи между 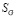 и
и 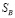 , и низкой между остальными парами индикаторов.
, и низкой между остальными парами индикаторов.
Функция ранжирования. Функция ранжирования в проекте «Вебометрический рейтинг научных учреждений России» [5] находится в процессе исследования и разработки, но для лучшего понимания процедуры сглаживания ошибок здесь стоит коротко остановиться на основных подходах к ее построению.
Обозначим 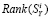 ранг i-го сайта по индикатору S, измеренному поисковой системой Яндекс. Здесь ранг – это порядковый номер сайта в упорядоченном по убыванию векторе
ранг i-го сайта по индикатору S, измеренному поисковой системой Яндекс. Здесь ранг – это порядковый номер сайта в упорядоченном по убыванию векторе 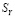 , то есть сайт с максимальным значением
, то есть сайт с максимальным значением 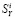 имеет ранг, равный 1. Для остальных индикаторов ранги определяются аналогично.
имеет ранг, равный 1. Для остальных индикаторов ранги определяются аналогично.
Для i-го сайта вычисляется интегральный показатель R(i) как функция от рангов сайта по каждому индикатору. Далее сайты упорядочиваются по возрастанию значений R(i), сайт с минимальным значением R(i) получает вебометрический ранг WR(i), равный 1, и т.д. В настоящее время R(i) определяется как сумма рангов i-го сайта.
При таком построении функции ранжирования WR в случае ошибочных значений вебометрических индикаторов нас интересуют, собственно говоря, не их реальные значения, а ранги по соответствующим индикаторам. Это замечание мы будем иметь в виду в следующем разделе.
Сглаживание ошибок. Сглаживанием ошибок поисковых систем будем называть процедуру вычисления правдоподобных значений индикаторов «размер сайта» вместо измеренных и представляющихся ошибочными значений с использованием данных о количестве страниц сайта, обнаруживаемых BeeCrawler.
Первым шагом такой процедуры является визуальное выявление подозрительных на ошибку значений 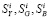 (с использованием графиков, аналогичных приведенному на рис. 1) и очистка таблицы значений вебометрических индикаторов от строк, соответствующих сайтам, у которых обнаружены такие значения.
(с использованием графиков, аналогичных приведенному на рис. 1) и очистка таблицы значений вебометрических индикаторов от строк, соответствующих сайтам, у которых обнаружены такие значения.
Обработка таблицы вебометрических индикаторов, измеренных в июне-июле 2013 года, выявила около 40 таких сайтов. После очистки значения коэффициентов корреляции изменились, теперь 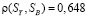 и
и 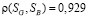 .
.
Предположим, что Яндекс формирует значения 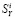 исходя из следующих правил:
исходя из следующих правил:
- на каждом уровне сайта индексируется часть страниц, и чем ниже уровень, тем меньше эта часть;
- чем больше внешних ссылок сделано на сайт, тем большее количество его страниц индексируется.
Эксперименты, проведенные с результатами работы BeeCrawler с учётом сделанных предположений, приводят нас к построению формулы следующего вида:
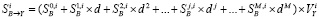 , (1)
, (1)
где 0<d<1 – коэффициент затухания, чем ниже уровень сайта, тем меньше страниц индексируется. Вычисления 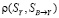 для очищенной таблицы индикаторов показывают, что максимальное значение коэффициента корреляции, равное 0,826, достигается при d=0,075 и M=7 (здесь, как и ранее
для очищенной таблицы индикаторов показывают, что максимальное значение коэффициента корреляции, равное 0,826, достигается при d=0,075 и M=7 (здесь, как и ранее 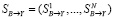 ).
).
Учитывая достаточно сильную статистическую зависимость между 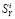 и
и 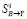 , для сглаживания ошибок Яндекса предлагается использовать соответствующие значения
, для сглаживания ошибок Яндекса предлагается использовать соответствующие значения 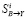 . Точнее, как было сказано ранее, нас интересуют не сами значения ошибочных
. Точнее, как было сказано ранее, нас интересуют не сами значения ошибочных 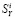 , а их
, а их 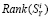 . Поэтому для ошибочного значения с индексом i по формуле (1) вычисляется
. Поэтому для ошибочного значения с индексом i по формуле (1) вычисляется 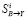 , далее определяется его ранг
, далее определяется его ранг 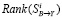 для вектора
для вектора 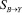 и полученное значение присваивается
и полученное значение присваивается 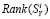 как правильное.
как правильное.
Эксперименты показали, что для Google также можно построить формулу следующего вида:
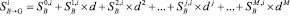 . (2)
. (2)
Обратим внимание на то, что индикатор ссылочной популярности сайта V в (2) не используется. Вычисления 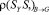 для очищенной таблицы индикаторов показывают, что максимальное значение коэффициента корреляции, равное 0,941, достигается при d=0,5 и M=7. Отсюда следует, что формулу (2) можно использовать для сглаживания ошибочных
для очищенной таблицы индикаторов показывают, что максимальное значение коэффициента корреляции, равное 0,941, достигается при d=0,5 и M=7. Отсюда следует, что формулу (2) можно использовать для сглаживания ошибочных  по аналогии с формулой (1) для Яндекса (хотя и корреляция между
по аналогии с формулой (1) для Яндекса (хотя и корреляция между  и
и 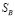 была уже достаточно большой).
была уже достаточно большой).
Заключение
В статье предложен подход к сглаживанию ошибок поисковых систем, возникающих при измерениях вебометрического индикатора «размер сайта». Данный подход применяется в проекте «Вебометрический рейтинг научных учреждений России» и в большинстве случаев позволяет использовать точные процедуры исправления очевидных ошибок вместо слабо формализуемых мнений экспертов, в качестве которых пока выступают сами разработчики проекта.
Работа выполняется при поддержке гранта РГНФ № 12-03-12001.
Библиографическая ссылка
Печников А.А. ОБ ИЗМЕРЕНИЯХ ВЕБОМЕТРИЧЕСКИХ ИНДИКАТОРОВ // Международный журнал экспериментального образования. 2013. № 10-2. С. 400-404;URL: https://expeducation.ru/en/article/view?id=4258 (дата обращения: 16.07.2026).